���������ר��Frank
������ҵ��ô���꣬�Ӵ������е�Ӧ�ã�Apple��Ӧ�ã�eBay��Ӧ�ú����ڰ����Ӧ�ã���Ȼ�����ڲ�ͬ�Ĺ�˾��ʹ���˲�ͬ�ļܹ�������һ����ͬ����Ƕ��ܸ��ӡ����¸����Ե�ԭ���кܶ࣬����Ӽܹ��IJ��濴����Ҫ�����㣬һ���Ǽܹ���ƹ��ڸ��ӣ����̫���ܰ������Ρ���һ���Ǹ�����û�ܹ���ServiceImpl��Ϊ�ϵ������һ�У�һ��ͱ��DAO���ͼ������ԣ�����Transaction ScriptҲ���պϣ�����ʵ�����ֶ��죩��������Ϊ�ĸ����Ե���ϵͳԽ��Խӷ�ף�Խ��Խ��ά���������ϴ��뷢��һ��������������ͬѧ������Ҫ���ű��ӿټ������������£���������ϵͳ��ҵ�����磬Ȼ����һͷ��������bug fix��ҵ�����Ķ���ѭ���У��������գ�
����CRM��Ϊ�������ϵ�Ӧ��ϵͳ����ȻҲ�Ӳ���������������������˵����ǿ�ʼ��˼������ʲô�����ϵͳ�����ԣ����ǵ����ܲ���ͨ���ܹ����������ָ����ԣ�������������㣬�����Ŷӿ�ʼ��һ�ηdz�������ļܹ��ع�֮�ã�Redefine theArch�����ڼ����Dzο���SalesForce��TMF2.0�����ͺ����ļܹ������������Sȡ�˺ܶ��м�ֵ�����룬�ٽ�������Լ���˼�������γ��������Լ����ڵĻ�����չ��+Ԫ����+CQRS+DDD��Ӧ�üܹ����üܹ����ص��ǿ���չ�Ժã��ܺõĹ᳹��OO˼�룬��һ�������Ĺ淶������������CQRS������ģ�������ںܴ�̶��Ͽ��Խ���Ӧ�õĸ��Ӷȡ�������Ҫ���������ǵ�˼�����̺ͼܹ�ʵ�֣�ϣ���ܶ���·�ϵ�������������
�����������������
�����������Ƿ��������ۣ������������ϵͳ�쳣���ӵ����������Ҫ���������ĸ����棺
��������չ�Բ�
��������ֻ��һ��ҵ��ļ�����������Ҫ��չ������Ҳ��ͻ������Ҳ��Ϊʲô����㾭�������Ե�ԭ����Ϊ���Ǵֵ�ϵͳ���Ǵӵ�һҵ��ʼ�ġ���������֧�ֵ�ҵ��Խ��Խ�࣬�������濪ʼ���ִ�����if-else�������ʱ����뿪ʼ�л�ζ����û�ŵ���ͬѧ����ô�������϶ѣ��ŵ���ͬѧ���ع�һ�£�����Ϊϵͳû��ͳһ�Ŀ���չ�ܹ����ع��ļ���Ҳ������ͬ�����ִ���IJ�һ����Ҳ��һ�������ϵĸ��Ӷȡ��ö���֮��ϵͳ�ͱ�ø�����ά����
����������CRMӦ�ã���N��ҵ��ÿ��ҵ������N���⻧�������Ҫ��if-else�ж�ҵ����죬�Ǽ�ֱ���DzҾ���御���ʵ������չ�㣨ExtensionPoint�������߽в����Plug-in��������ڼܹ�������Ƿdz��ձ�ġ��Ƚϳɹ��İ�����eclipse��plug-in���ƣ����ŵ�TMF2.0�ܹ�������һ����չ����������ֶ���չ����һ���SaaSӦ����Ϊ��Ҫ����Ϊ�кܶ�ͻ����ƻ����������Ǻܶ�ϵͳҲû��ͳһ���ֶ���չ������
�����������
�����ǵģ������������ܶ�ʱ�����Ƕ��Dz��������������Ը���������̵Ĺ��������������һ�����ԣ�����һ��˼ά��ʽ�����������Ƽ��㡢���ѧϰ����������Щ�����ȵ��ʱ�������������Լ������Dz������������OOD��������ǿ������ʦҪ�߱�ҵ��Sense����ƷSense������Sense���㷨Sense��XXSense��ʱ���Dz��Ǻ����˶Թ���������Ҫ��
�������ҹ۲�ֹ���ʦ���������Լ�����OO������Զû�дﵽ��ͨ�ij̶ȣ�����OO˼���ȱ����Ҫ�������������棬һ���Ǻܶ�ͬѧ���˽�SOLIDԭ�������ģʽ�����ửUMLͼ������ֻ��֪�����������������õ�ʵ���У���һ���Dz����������ģ����������ģ�����Ѿ��ܶ��ˣ��ҵĹ۵���DDD�ܺã��������������úͲ���ȡ���ڳ�����������������������ƫ�����úõ��ж�һ��EricEvans�ġ�����������ơ����������֪�����ĸ���ϲ�㣬������ˡ�
�����Ҹ�����ΪDDD���ĺô��ǽ�ҵ���������ֻ�����ԭ�Ȼ�ɬ�Ѷ���ҵ���㷨����ͨ���������Domain Object����ͳһ���ԣ�Ubiquitous Language��������������������Ի���������������ң����ֱ�������Ĵ���ɶ��Ե����������ý����������˶����Ļ��ж��ġ�����Abelson��һ�仰��
����Programs must be written for people to read, and only incidentally for machines to execute.
��������ǿ��Ǵ����Щ�������˸��ܵı�����Ϊ��
�ֲ㲻����
������˵�ĺã�All problemsin computer science can be solved by another level of indirection���������ѧ������κ����ⶼ����ͨ������һ����ӵ��м������������������Dz��Ǹ��ܵ���Ӳ��ǿ���ˡ��ֲ����ĺô����Ƿ����ע�㣬��ÿһ��ֻ����ò��ע�����⣬�Ӷ������ӵ�������ֶ���֮�����á�����ƽʱ������MVC��pipeline���Լ�����valve��ģʽ���������������
�����ðɣ����Dz��Dz��Խ��Խ�ã�Խ����ء���Ȼ���ǣ������ҿ�ƪ˵�ģ�����IJ�β������ܴ����ô�������������ϵͳ�ĸ����Ժͽ���ϵͳ���ܡ�����ISO�������߲�Э����˵��������߲�ֵĺ�������ܺã���Ҳ�ܷ������IJ������ٱ�����ǰ���ᵽ�Ĺ�����Ƶ����ӣ����û�Ǵ��Ļ�Ӧ����Apple��Directory ServiceӦ�ã�����ϵͳ��7��֮�࣬��ʲôvalidator��assembler������һ��������Դ����ܲ�����ô�����Էֲ�̫���û�зֲ㶼�ᵼ��ϵͳ���Ӷȵ�������������ǵ�ԭ���Dz�����û�зֲ㣬����ֻ���б�Ҫ�IJ㡣
������������
����������������Ϊȱ�ٹ淶��Լ��������淶�dz��dz��dz�����Ҫ����Ҫ����˵���飩����Ҳ�������ױ����ӵĵ㣬�������Ǽܹ���consistency�������ƻ�������Ŀ�ά���Խ������½��������������ܹ�����ͬ���衣��ͬѧ��˵�����Ǹ�naming������ô�������Ǹ��ְ�������ô��������2��module����3��module������ô��ֻҪ����������������Щ���ⶼ��С���⡣�ǵģ�������Щͬѧ�����ٶ�����һ������“Just because you can, doesn’t mean you should”������package��˵������������һ����һ����ĵط�������һ�ֱ�����ƣ����㽫һЩ��ŵ�Package��ʱ���൱�ڸ�����һλ��������ƵĿ�����ԱҪ����Щ�����һ���ǡ�
��������ܷ�������ʵ�ܹǸУ��淶��ִ���Ǹ������⣬������ڼܹ��������Լ�������������Ǽܹ��У���չ�������ExtPt��β����չʵ�ֱ�����Ext��β���㲻��ôд�ͻ�������쳣�����Ǽܹ���Լ���Ͼ����ޣ�����Ļ���Ҫ��Code Review����ʱû�뵽ʲô���õİ취�����ֶԼܹ�Լ���Ľ����Ͽ�follow��ȷ����ϵͳ��consistency�������γ���һ�������������䣨����ͼ��ʾ���������Һ��Ŷ�˵�ģ���������������Ķ���ʱ��Ӧ�ÿ�����Hash����һ����ֱ�Ӷ�λ����Ӧ��module����Ӧ��package�����Ӧ��class�������ǵ�“һ����”��ȥ�����١�
�������½������һ��������ϵͳ�бȽϵ��͵Ĵ��룬Ҳ������Դ��п������Լ�Ӧ�õ�Ӱ�ӡ�
������Ӧ��֮��
����֪�����������ڣ��������������������һ���������Щ����ġ���ͷվ��ɽ���ٿ���Щ�������ʱ��ÿ��������Ϊ�棬�����㻹“���ڴ�ɽ��”��ʱ����������������������ɽ��ȫò�Ĺ��̣��������������ô���ס����ҵ������Ŷ��ڼ��Ѱ���֮���������ջ�
����1����չ�����
������չ������˼����Ҫ������TMF2.0����������ʵ�������˼��Ҳһֱ���ã��������ھֲ��Ĵ����ع����Ż����������Strategy Pattern����չ������һֱû���ҵ�һ���ܺõĹ̻�������еķ�����ֱ����¬���Ŷӷ������������������ؼ�����ʾ��һ����ҵ������ʶ�������Ļ�˵�������ʱTMF1.0���������ʶ��Ļ�����û��TMF2.0ʲô���ˣ���һ���dz������չ����ơ�
��������ʶ��
����ҵ������ʶ�������ǵ�Ӧ���зdz���Ҫ����Ϊ���ǵ�CRMϵͳҪ����ͬ��ҵ������ÿ��ҵ�����ж���⻧�������й����ۣ��й��ĵ����й��̼Ҷ��Dz�ͬ��ҵ�����ĵ��µ�ÿ����˾���й��̼��µ�ÿ����Ӧ�����Dz�ͬ���⻧�����Դ�ͳ�Ļ��ڶ��⻧��TenantId����ҵ������ʶ�����������ǵ�Ҫ�������ڴ˻�����������������ҵ���루BizCode������ʶҵ��
�����������ǵ�ҵ������ʵ�����ǣ�BizCode��TenantId����Ԫ�顣��ÿһ��ҵ���������棬�ֿ����ж����չ�㣨ExtensionPoint��������һ����չ��ʵ�֣�Extension��ʵ������һ����ά�ռ��е����������Maven Coordinate�ĸ����Ҹ������˸����ֽ���չ���꣨Extension Coordinate���������������ã�ExtensionPoint��BizCode��TenantId����Ψһ��ʶ��
��չ��
������չ�������������ģ����е���չ�㣨ExtensionPoint������ͨ���ӿ���������չʵ�֣�Extension����ͨ��Annotation�ķ�ʽ��ע�ģ�Extension����ʹ��BizCode��TenantId��������������ʶ���ݣ���ܵ�Bootstrap�����Spring������ʱ������ɨ�裬����Extensionע�ᣬ��Runtime��ʱ��ͨ��TenantContext��ѡ��Ҫʹ�õ�Extension��TenantContext��ͨ��Interceptor�ڵ���ҵ����֮ǰ���г�ʼ���ġ�������������ͼ��ʾ��
2���������
��������ģ
����ȷ��˵DDD����һ���ܹ�������˼��ͷ����ۡ������ڼܹ��������Dz�û��ǿ��Լ��Ҫʹ��DDD�������������������ĸ���ҵ��������ǿ�ҽ���ʹ��DDD��������ű���TS: Transaction Script������ΪTS��ƶѪģʽ������ֻ�����ݽṹ����ȫû�ж�������+��Ϊ���ĸ����Ҳ��Ϊʲô���ǽ�����������̵�ԭ��Ȼ��DDD���������ģ���һ��֪ʶ�ḻ����ƣ�Knowledge Rich Design������ô���⣿������ͨ���������Domain Object�����������ԣ�Ubiquitous Language�������ĵ��������ͨ���������ʽ����������Ӷ����Ӵ���Ŀ������ԡ������������IJ�������ҵ�����“����”�����е�ҵ��������ͬʵ��һ��������Ҫ��ȷ�ı��������
��������ǰ����ʹ���ͼ����չʾ�ģ�������ԣ�DistributionPolicy�������������һ��ҵ�����У�û����֪�����Ǹ�ʲô�ģ�Ҳ�����������һ����Ҫ���������ȥ���ӡ������������������Գ���������һ��������������DistributionPolicy���������һ���������ˣ�Ŷ������һ��������ԣ����������ʹ�����������Ķ��ˣ������µIJ���Ҳ�����㣬����Ҫ��ԭ���Ĵ����ˡ�
��������˵�õĴ��벻��Ҫ�ó���Ա�ܶ�������Ҫ��������ר��Ҳ�ܶ������ٱ�����CRM�����У�������˽���Ƿdz���Ҫ����������������أ�Territory�����ֵģ�ÿ��������Աֻ������˽�����Լ���أ��ڵĿͻ�������Խ�硣���������ǵĴ�����ȴû��������ʵ�壨Entity����Ҳû����Ӧ�����Ժ����Ӧ����͵���������ר�������ģ��������ճ���ͨ�ģ��Լ�����ģ�ͺʹ�����ֵĶ�������ѵģ�û�й����ԡ��������ϵͳά����ͬѧ����˼�������ţ���Ϊ���й��ڹ���˽���IJ���������ɢ���Ÿ�����repeat itself�������룬���¿�����Ҳû�취ά����
�������Ե���ѧ�������������������ʵ��֮������ģ�ͺʹ��붼һ���ӱ������ܶࡣ�ڼ���������ܵİ�ҵ��������ֻ�������������˴���Ŀɶ��ԺͿ���չ�ԡ�����ѧ�Ļ�˵����DDDд���룬���ҵ��˴����ĸо���������������ũʽCoding����ͼ��������ļ�Ҫ����ģ�ͣ����������ܱ����������ĺ���������
��������CQRS��Ҫ˵һ�£�����ֻʹ����Command��Query����ĸ����û��ʹ��Event Sourcing��ԭ��ܼ�—����Ҫ������Command��ʵ������ʹ��������ģʽ�������ǰ��ServiceImpl��ְ���ֻ��һ��Facade�����еĴ���������CommandExecutor���档
����SOLID
����SOLID�ǵ�һְ��ԭ��(SRP)������ԭ��(OCP)�������滻ԭ��(LSP)���ӿڸ���ԭ��(ISP)����������ԭ��(DIP)����д��ԭ����Ҫ��ģʽ��Design Pattern������������Ҫ��ָ���������������Ƶ�Bible����������Ἣ����������ǵ�OOD�����ʹ����������������ڿ�ƪ�ᵽ��ServiceImpl�ϵ�������ӣ������Ծ���Υ���˵�һְ����һ������������鶼���ˣ��Ѳ�����Ĺ���Ҳ���Լ�����������������ھ��Ծͻ�ܲ�ھ��Բ���´�����ѱ����ã����ܸ��ã�ֻ�ܸ��ƣ�Repeat Yourself������������һ�����顣
�����ٱ�����javaӦ����ʹ��logger����кܶ�ѡ��ʲôlog4j��logback��common logging�ȣ�ÿ��logger��API���÷������в�ͬ���е���Ҫ��isLoggable()������Ԥ�ж��Ա�������ܣ��е�����Ҫ������Ҫ�л���ͬ��logger��ܵ����Σ�����ͷ���ˣ��п���Ҫ�Ķ��ܶ�ط���������Щ�����ԭ��������ֱ��������logger��ܣ�Ӧ�úͿ�ܵ�����Ժܸߡ�
������ô�ƣ� ��ѭ����������ԭ����ܺ���������������þ����㲻Ҫֱ�������ң�����Ҷ�ͬʱ����һ���ӿڣ�������ʱ��Ҳ������ӿڵı�̣�����������֮��ͽ����ˣ������ͱ����������������ɸĶ��ˡ�
���������ǵĿ������У����ֶ�SOLID����ѭҲ���洦�ɼ���Service Facade���˼�������ڵ�һְ��SRP����չ����Ʒ��Ϲر�ԭ��OCP����־��ƣ��Լ�Repository��Tunnel�Ľ������õ�����������DIPԭ�������ĵ㻹�кܶ࣬�Ͳ�һһö���ˡ���Ȼ�ˣ�SOLID����OO��ȫ�����������������ģʽ���ܹ�ģʽ��UML���Լ��Ķ�������Դ�루���ǵ�Command��ƾ��Dzο���Activiti��Command��Ҳ������Ҫ��ֻ��SOLID������������Ҫ���������������ص��ó�����һ�£�ϣ���ܵõ���ҵ����ӡ�
����3���ֲ����
������һ�����ƱȽ�ֱ�ۣ�����Ӧ�ò㻮��Ϊ������IJ�Σ��ֱ���App�㣬Domain���Repostiory�㡣
����1.App����Ҫ�����ȡ���룬��װcontext��������У�飬������Ϣ���������ҵ����������ȷ����Ϣ�������Ҫ�Ļ�ʹ��MetaQ������Ϣ֪ͨ��
����2.Domain����Ҫ��ͨ���������Domain Service�����������Domain Object���Ľ��������ϲ��ṩҵ�����Ĵ�����Ȼ������²�Repository���־û�������
����3.Repository����Ҫ�������ݵ�CRUD�������������ǽ����˺���������ͨ����Tunnel���ĸ��ͨ��Tunnel�ij�����������ξ����������Դ����Դ������MySQL��NoSql��Search��������HSF�ȡ�
����������Ҫע����Ǵ�����ϵͳ��ȡ���������н������ģ�Bounded Context���µ����ݣ�Ϊ���ֺ�Bounded Context�µ�����Gap��ͨ�������ַ�ʽ��һ�����ô�����Big Domain�������ߵIJ��춼����������һ�������ӷ����㣨Anticorruption Layer����ת����ʲô��Bounded Context�� ����һ�£��������ǵ���������������÷�Χ�ģ�Context���ģ�����ҡͷ������������й���Context�±�ʾNO��������ӡ�ȵ�Context��ȴ��YES��
����4���淶���
�������ǹ淶�����Ҫ��Ҫ��������ԭ�������Լ�����Ŷ�λ�ö�����Ҫ�ҷţ����ǵ�ÿһ�������Module����ÿһ������Package��������ȷ��ְ����ͷ�Χ�������ԷŴ�������extension����ֻ����������չʵ�ֵģ���������������������Interceptor����ֻ�Ƿ��������ģ�validator����ֻ�Ƿ�У�����ġ����ǵ���Ҫ��������ͼ��ʾ��
���ñ�ǩ
�����������ں���λ�ú�Ҫ���Ϻ��ʵı�ǩ��Ҳ����Ҫ���չ淶�����������������Ǽܹ�����������йص�Object����Ҫ��Client Object��Domain Object��Data Object��Client Object�Ƿ��ڶ������к��ⲿ����ʹ�õ�DTO��������������CO��β����Ӧ��Data Object��Ҫ�dz־ò�ʹ�õģ�����������DO��β���������Ӧ���������ģ�self-evident)��Ҳ���ǿ���������֪�������Ǹ���ʲô�£���Ҳ�ͷ���Ҫ�����ǵ���Ҳ�����ǵ�һְ��ģ�Single Responsibility���ģ�������������鲻��������ȻҲ�ͺ��������ˡ��������Class Name�������ģ�Package Name�������ģ�Module NameҲ�������ģ���ô��������Ӧ��ϵͳ�ͻ�����ױ����⣬�������ͻ�������ά��Ч�ʻ���ߺܶࡣ���ǵ�������������ͼ��ʾ��
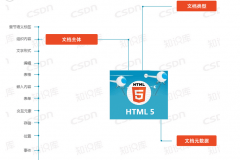
GTSӦ�üܹ�
������������ij�ƪ���ۣ���ϣ���Ұ����ǵļܹ������������ˣ�����ٴ������Ͽ������ǵļܹ��ɡ�������ò�����Ҳ����framework code�������Լ���һ�¡�
��������ܹ�
�������ǵļܹ�ԭ��ܼ����ڸ��ھۣ�����ϣ�����չ����������ָ��˼���£������ܵĹ᳹OO�����˼���ԭ�����������γɵļܹ��Ǽ�������չ��+Ԫ����+CQRS+DDD��˼�룬����Ԫ����ǰ��û��ô�ᵽ��������˵һ�£������ֶ���չ����һ��Ľ����������Ԥ����չ�ֶΣ�����һ��ľ���ʹ��Ԫ�������档
����ʹ��Ԫ���ݵĺô��Dz�����֧���ֶ���չ�����ṩ�˷ḻ���ֶ�������������Ϊ�Ժ��SaaS�������ṩ�˿����ԣ���������ѡ����ʹ��Ԫ�������档��DDDһ����Ԫ����Ҳ�ǿ�ѡ�ģ������û���ֶ���չ�����Ͳ�Ҫ�á���������ܹ�ͼ���£�
ת����ע���� ����ת���ԣ���˼��Դ�� http://www.aseoe.com/show-63-1120-1.html

![��Ĭ���ģ���ʲô��û�У�ֻ��һ�����ӣ�����Ů�������� �C [������Ȥ]](http://www.aseoe.com/statics/images/nopic.gif)