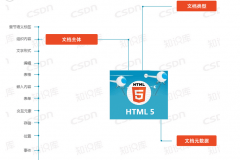
����1. ʲô��“���ʸ���”��
������Щͬѧ���ܲ�̫���“���ʸ���”��ָʲô���������һ�����͵�“���ʸ���”��
�����û�ѡ��һ���ı��������ʣ��������Զ������ѡȡ���ı����Ӹ����������û����Ժܷ����Ϊ��ҳ�������߱ʼǡ�
��������ǰ��ʱ��Ϊ����ҵ��ʵ����һ�������ݽṹ����ϵ��ı��������߱ʼǹ��ܡ��������ָ����ҪΪ�������ܽ��������ҳ�� DOM �ṹ�����������ܶ�ҵ����������ù��ܺ��IJ��־��н�ǿ��ͨ��������ֲ�ԣ����ó����ʹ�ҷ�������һ�¡�
�������ľ���ĺ��Ĵ����ѷ�װ�ɶ����� web-highlighter���Ķ����������ʿɲο����д���↓↓��

����2. ʵ��“���ʸ���”��Ҫ�����Щ���⣿
����ʵ��һ��“���ʸ���”�����߱ʼǹ�����Ҫ����ĺ���������������
�����Ӹ�������������θ����û�����ҳ�ϵ�ѡȡ��Ϊ��Ӧ���ı����Ӹ���������
������������ij־û��뻹ԭ������α����û�������Ϣ�������´����ʱȷ��ԭ�������´δ�ҳ���û���������Ϣ�Ͷ�ʧ�ˡ�
����һ����˵�����ʸ�����ҵ��������Ҫ������Լ����������ݣ�����ԱȽ�������������ҳ�ϵ��Ű桢HTML ��ǩ�ȷ�����п��ơ���������£�������������������һЩ���Ͼ��Լ����Ը��ݸ�����������������ݵ� HTML��
������������Ե�����ǣ�ҳ�� HTML �Ű�ṹ���ӣ��������ݸ����������ƶ�ҵ��Ķ� HTML����Ҳ�������˶Խ��������ͨ�û���Ҫ��Ŀ����ǣ�����������ݾ���“���ʸ���”��֧�ֺ�������ʱ��ԭ����״̬��������ȥ�������ݵ���֯�ṹ��
���������������˵˵����ν������������������⡣
����3. ���“�Ӹ�������”��
�������ݶ�ͼ��ʾ���ǿ���֪�����û�ѡ��ijһ���ı������ij�Ϊ“�û�ѡ��”�������ǻ������ı���һ������������
���������û�ѡ������ͼ�е��ı�������ɫ���֣���Ϊ��Ӹ����Ļ���˼·���£�
������ȡѡ�е��ı��ڵ㣺ͨ���û�ѡ���������Ϣ����ȡ���б�ѡ�е������ı��ڵ㣻
����Ϊ�ı��ڵ����ӱ���ɫ������Щ�ı��ڵ����һ���µ�Ԫ�أ���Ԫ�ؾ���ָ���ı�����ɫ��
����3.1. ��λ�ȡѡ�е��ı��ڵ㣿
����1��Selection API
������Ҫ���������Ϊ�����ṩ�� Selection API �����ļ����Ի����������Ҫ֧�ָ��Ͱ汾�����������Ҫ�� polyfill��
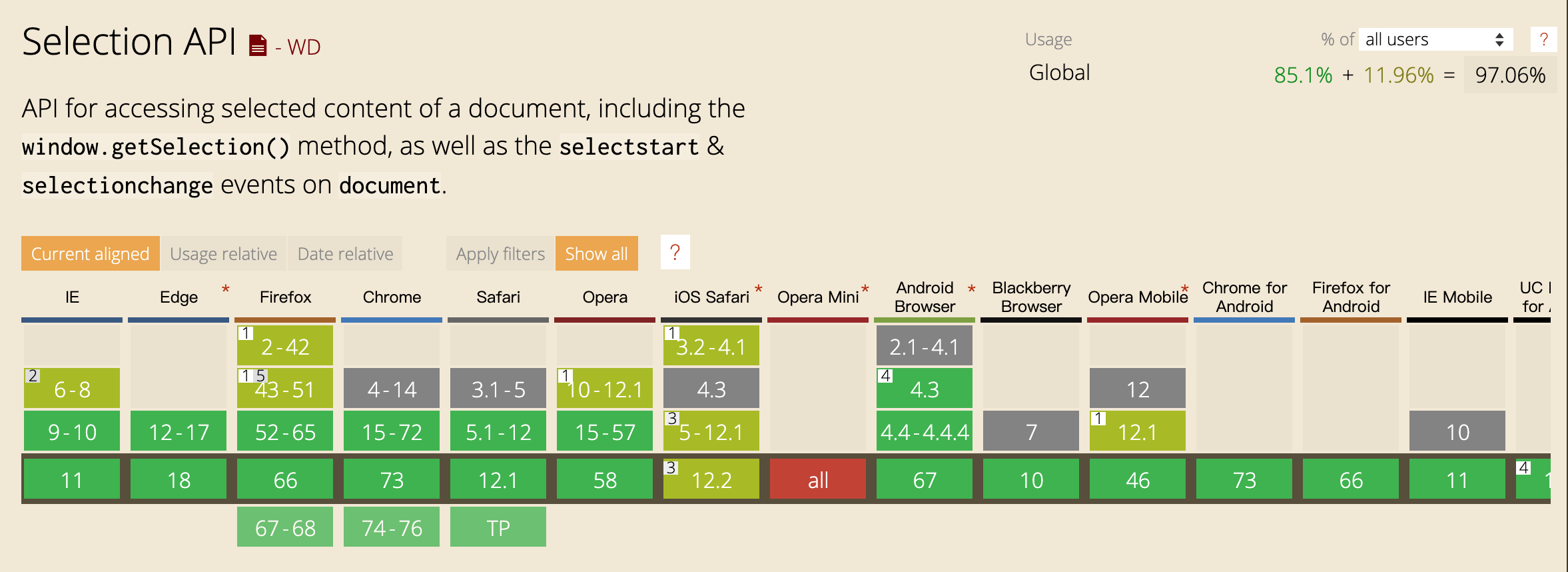
����Selection API ���Է���һϵ�й����û�ѡ������Ϣ����ô�Dz��ǿ���ͨ����ֱ�ӻ�ȡѡȡ�е����� DOM Ԫ���أ�
�������ź������ܡ������������Է���ѡ������β�ڵ���Ϣ��
- const range = window.getSelection().getRangeAt(0);
- const start = {
- node: range.startContainer,
- offset: range.startOffset
- };
- const end = {
- node: range.endContainer,
- offset: range.endOffset
- };
����Range ���������ѡ���Ŀ�ʼ�������Ϣ�����а����ڵ㣨node�����ı�ƫ������offset�����ڵ���Ϣ���ö�˵���������һ�� offset ��ָʲô�����磬��ǩ
����һ���ı���ʾ��
���û�ѡȡ�IJ�����“һ���ı�”���ĸ��֣���ʱ��β�� node ��Ϊ p Ԫ���ڵ��ı��ڵ㣨Text Node������ startOffset �� endOffset �ֱ�Ϊ 2 �� 6��
����2����β�ı��ڵ���
���������� offset �ĸ������Ȼ�ͷ����и�������Ҫ����������û�ѡ����selection������ֻ����һ���ı��ڵ��һ���֣��� offset ��Ϊ 0���������������õ����û�ѡ���������Ľڵ��Ҳֻϣ������β�ı��ڵ����“һ����”���Դˣ����ǿ���ʹ�� .splitText() ����ı��ڵ㣺
��
- // �ڵ�
- if (curNode === $startNode) {
- if (curNode.nodeType === 3) {
- curNode.splitText(startOffset);
- const node = curNode.nextSibling;
- selectedNodes.push(node);
- }
- }
- // β�ڵ�
- if (curNode === $endNode) {
- if (curNode.nodeType === 3) {
- const node = curNode;
- node.splitText(endOffset);
- selectedNodes.push(node);
- }
- }
�������ϴ�������� offset ���ı��ڵ���в�֡����ڿ�ʼ�ڵ㣬ֻ��Ҫ�ռ����ĺ�벿�֣������ڽ����ڵ�����ǰ�벿�֡�
����3������ DOM ��
������ĿǰΪֹ������ȷ�ҵ�����β�ڵ㣬������һ�������ҳ�“�м�”���е��ı��ڵ㡣�����Ҫ���� DOM ����
����“�м�”������������Ϊ�����Ӿ�����Щ�ڵ���λ����β֮��ģ������� DOM �������Խṹ�������νṹ���������“�м�”���ɳ������ԣ�����ָ������ȱ���ʱ��λ����β���ڵ�֮��������ı��ڵ㡣DFS �ķ����кܶ࣬���Եݹ飬Ҳ������ջ+ѭ��������Ͳ����ˡ�
������Ҫ��һ�µ��ǣ�����������ҪΪ�ı��ڵ����Ӹ�������������ڱ���ʱֻ���ռ��ı��ڵ㡣
- if (curNode.nodeType === 3) {
- selectedNodes.push(curNode);
- }
����3.2. ���Ϊ�ı��ڵ����ӱ���ɫ��
������һ�������������ѡ�����һ���Ļ����ϣ������Ѿ�ѡ�������б��û�ѡ�е� �ı��ڵ㣨������ֺ����β�ڵ㣩���Դˣ�һ����ֱ�ӵķ�������Ϊ��“������”һ����������ʽ��Ԫ�ء�
��������ģ����ǿ��Ը�ÿ���ı��ڵ������һ�� class Ϊ highlight �� Ԫ�أ���������ʽ��ͨ�� CSS .highlight ѡ�������á�
- // ʹ����һ���з�װ�ķ�����ȡѡ���ڵ��ı��ڵ�
- const nodes = getSelectedNodes(start, end);
- nodes.forEach(node => {
- const wrap = document.createElement('span');
- wrap.setAttribute('class', 'highlight');
- wrap.appendChild(node.cloneNode(false));
- node.parentNode.replaceChild(wrap);
- });
- .highlight {
- background: #ff9;
- }
���������Ϳ��Ը���ѡ�е���������һ��“����”�ĸ��������ˡ�
����p.s. ѡ�����غ�����
����Ȼ�����ı������ﻹ��һ���Ƚϼ��ֵ����� —— ����������غϡ��ٸ����ӣ��ʼ����ʾͼ����ͼ�����һ����������͵ڶ�����������֮������ص����֣���“�������”�ĸ��֡�
�����������Ŀǰ�����ƺ����������⣬���ڽ������Ҫ�ᵽ��һЩ����������ʱ���ͻ��ɷdz��鷳���������������У�һЩ��Դ����鴦��Ҳ���������⣬��Ҳ��û��ѡ�����ǵ�һ��ԭ���������һ�£����������һ�ŵ�������Ӧ�ĵط�����ϸ˵��
����4. ���ʵ�ָ���ѡ���ij־û��뻹ԭ��
������Ŀǰ�����Ѿ����Ը�ѡ�е��ı����Ӹ��������ˡ�������һ�������⣺
��������һ�£��û��������˺ܶ��ص㣨�����������ĵ��˳�ҳ����´η���ʱ������Щ�����ܱ���ʱ�����ж�ô�þ�ɥ����ˣ����ֻ����ҳ������“һ����”���ı�������������ʹ�ü�ֵ���͡���Ҳ�ʹ�ʹ���ǵ�“���ʸ���”����Ҫ�ܹ����棨�־û�����Щ����ѡ������ȷ��ԭ��
�־û�����ѡ���ĺ������ҵ�һ�ֺ��ʵ� DOM �ڵ����л�������
����ͨ���������ֿ���֪������ȷ������β�ڵ����ı�ƫ�ƣ�offset����Ϣ����Ϊ����ı��ڵ����ӱ���ɫ�����У�offset ����ֵ���ͣ�Ҫ�ڷ�������������Ȼû�����⣻���� DOM �ڵ㲻ͬ����������б�����ֻ��Ҫ��ֵ��һ�������������ں�˱�����ν�� DOM ����ôֱ���ˡ�
����4.1 ���л� DOM �ڵ��ʶ
������������ĺ��ĵ�����ҵ�һ�ַ������ܹ���λ DOM �ڵ㣬ͬʱ���Ա��������ͨ�� JSON Object�����Դ�����˱��棬��������ڱ����б���Ϊ DOM ��ʶ ��“���л�”�����´��û�����ʱ���ֿ��ԴӺ��ȡ�أ�Ȼ��“�����л�”Ϊ��Ӧ�� DOM �ڵ㡣
�����м��ֳ����ķ�ʽ����ʶ DOM �ڵ㣺
����ʹ�� xPath
����ʹ�� CSS Selector �
����ʹ�� tagName + index
��������ѡ����ʹ�õ����ַ�ʽ������ʵ�֡���Ҫע��һ�㣬����ͨ�� Selection API ȡ������β�ڵ�һ�����ı��ڵ㣬������Ҫ��¼�� tagName �� index ���Ǹ��ı��ڵ�ĸ�Ԫ�ؽڵ㣨Element Node���ģ��� childIndex ��ʾ���ı��ڵ����丸�ĵڼ������ӣ�
- function serialize(textNode, root = document) {
- const node = textNode.parentElement;
- let childIndex = -1;
- for (let i = 0; i < node.childNodes.length; i++) {
- if (textNode === node.childNodes[i]) {
- childIndex = i;
- break;
- }
- }
- const tagName = node.tagName;
- const list = root.getElementsByTagName(tagName);
- for (let index = 0; index < list.length; index++) {
- if (node === list[index]) {
- return {tagName, index, childIndex};
- }
- }
- return {tagName, index: -1, childIndex};
- }
����ͨ���÷������ص���Ϣ���ټ��� offset ��Ϣ������λѡȡ����ʼλ�ã�ͬʱҲ��ȫ�ɷ�����˽��б����ˡ�
����4.2 �����л� DOM �ڵ�
����������һ�ڵ����л��������Ӻ�˻�ȡ�����ݺ��Ժ��������л�Ϊ DOM �ڵ㣺
- function deSerialize(meta, root = document) {
- const {tagName, index, childIndex} = meta;
- const parent = root.getElementsByTagName(tagName)[index];
- return parent.childNodes[childIndex];
- }
�������ˣ����Ǵ����Ѿ�����������������⣬���ƺ��Ѿ���һ�����ð汾�ˡ�����ʵ��Ȼ������ʵ�����飬���������������Щ��������������Ӧ��ʵ������ģ�����һЩ“��������”��
���������û��ģ�����������˵˵��ν��“��������”��ʲô����������ν����ʵ��һ������ҵ����õ�ͨ��“���ʸ���”���ܵġ�
����5. ���ʵ��һ�������������õ�“���ʸ���”��
����1������ķ�����ʲô���⣿
������������������ķ�������ʲô���⡣
������������Ҫ�����ı�ʱ����Ϊ�ı��ڵ����spanԪ�أ���Ķ���ҳ��� DOM �ṹ�������ܻᵼ�º�����������β�ڵ����� offset ��Ϣ��ʵ�ǻ��ڱ��Ķ���� DOM �ṹ�ġ������Ľ����������
�����´η���ʱ��������밴�ϴ��û�������˳��ԭ��
�����û���������ȡ����ɾ������������ֻ�ܰ�����˳��Ӻ���ǰɾ��
�������ͻ��в��ֵĸ���ѡ���ڻ�ԭʱ����λ����ȷ��Ԫ�ء�
�������ֿ��ܲ������⣬�����Ҿٸ�������ֱ�۽�����������⡣
- <p>
- �dz����˽����ܹ�������ʹ�ҷ���һ���ı����������߱ʼǣ���ʵ�ַ�ʽ��
- </p>
��������������� HTML���û��ֱ�˳��������������֣�“����”��“�ı�����”����ô���������ʵ�ַ�ʽ����� HTML ���������������
- <p>
- �dz�
- <span class="highlight">����</span>
- �����ܹ�������ʹ�ҷ���һ��
- <span class="highlight">�ı�����</span>
- �����߱ʼǣ���ʵ�ַ�ʽ��
- </p>
������Ӧ���������л����ݷֱ�Ϊ��
- // “����”�����ֱ�����ʱ��ȡ�����л���Ϣ
- {
- start: {
- tagName: 'p',
- index: 0,
- childIndex: 0,
- offset: 2
- },
- end: {
- tagName: 'p',
- index: 0,
- childIndex: 0,
- offset: 4
- }
- }
��
- // “�ı�����”�ĸ��ֱ�����ʱ��ȡ�����л���Ϣ��
- // ��ʱ������p�����Ѿ�������һ��������Ϣ����“����”����
- // �������ڲ� HTML �ṹ�ѱ��ģ�ֱ����˵���� childNodes �ı��ˡ�
- // ������childIndex��������ǰһ�� span Ԫ�صļ��룬��Ϊ�� 2��
- {
- start: {
- tagName: 'p',
- index: 0,
- childIndex: 2,
- offset: 14
- },
- end: {
- tagName: 'p',
- index: 0,
- childIndex: 2,
- offset: 18
- }
- }
�������Կ�����“�ı�����”���ĸ��ֵ���β�ڵ�� childIndex ������Ϊ 2����������ǰһ����������ı���
Ԫ���µ�DOM�ṹ�������ʱ“����”ѡ���ĸ������û�ȡ������ô�´��ٷ���ҳ�������ԭ������ —— “����”ѡ���ĸ�����ȡ���ˣ�
����Ȼ�Ͳ�����ֵ����� childNode����ô childIndex Ϊ 2 ���Ҳ�����Ӧ�Ľڵ��ˡ���͵��´洢�������ڻ�ԭ����ѡ��ʱ�������⡣
�������⣬���ǵ��ڵ�������ĩβ�ᵽ�ĸ���ѡȡ�غ�����ô��֧��ѡȡ�غϺ����׳������µİ���Ԫ��Ƕ�������
- <p>
- �dz�
- <span class="highlight">����</span>
- �����ܹ�������ʹ�ҷ���һ��
- <span class="highlight">
- �ı�
- <span class="highlight">����</span>
- </span>
- �����߱ʼǣ���ʵ�ַ�ʽ��
- </p>
������Ҳʹ��ij���ı�������θ�����ȡ�������������ԭ HTML ҳ�治ͬ�ĸ���Ƕ�ṹ������Ԥ����������ʹ�� xpath �� CSS selector ��Ϊ DOM ��ʶʱ�������ᵽ������Ҳ����֣�ͬʱҲʹ���������ʵ�ָ��Ӹ��ӡ�
���������������һ��������Դ����Ʒ����δ���ѡ���غ�����ģ�
������Դ�� Rangy ��һ�� Highlighter ģ�����ʵ���ı��������������ѡ���غϵ�����ǽ�����ѡ��ֱ�Ӻϲ��ˣ����Dz��Ϸ�����ҵ������ġ�
�������Ѳ�Ʒ Diigo ֱ�Ӳ�����ѡ�����غϡ�
����Medium.com ��֧��ѡ���غϵģ�����dz���������Ҳ�����Dz�Ʒ��Ŀ�ꡣ����ҳ����������ṹ�������Ե�������������ɿء�
����������ν����Щ�����أ�
����2����һ�����л� / �����л���ʽ
�����һ�Ե��IJ����ᵽ�����л���ʽ���иĽ�����Ȼ��¼�ı��ڵ�ĸ��ڵ� tagName �� index�������ټ�¼�ı��ڵ��� childNodes �е� index �� offset�����Ǽ�¼��ʼ��������λ����������Ԫ�ؽڵ��е��ı�ƫ������
��������������� HTML��
- <p>
- �dz�
- <span class="highlight">����</span>
- �����ܹ�������ʹ�ҷ���һ��
- <span class="highlight">�ı�����</span>
- �����߱ʼǣ���ʵ�ַ�ʽ��
- </p>
��������“�ı�����”�������ѡ����֮ǰ���ڱ�ʶ�ı���ʼλ�õ���ϢΪchildIndex = 2, offset = 14�������ڱ�Ϊoffset = 18����
Ԫ���µ�һ���ı�“��”��ʼ���㣬����18���ַ�����“��”�������Կ�����������ʾ���ŵ��ǣ�����
�ڲ�ԭ�е��ı��ڵ㱻���������ڵ���ηָ������Ӱ�����ѡ����ԭʱ�Ľڵ㶨λ��
�����ݴˣ������л�ʱ��������Ҫһ�����������ı��ڵ���ƫ����“����”Ϊ���Ӧ�ĸ��ڵ��ڲ��������ı�ƫ������
- function getTextPreOffset(root, text) {
- const nodeStack = [root];
- let curNode = null;
- let offset = 0;
- while (curNode = nodeStack.pop()) {
- const children = curNode.childNodes;
- for (let i = children.length - 1; i >= 0; i--) {
- nodeStack.push(children[i]);
- }
- if (curNode.nodeType === 3 && curNode !== text) {
- offset += curNode.textContent.length;
- }
- else if (curNode.nodeType === 3) {
- break;
- }
- }
- return offset;
- }
��������ԭ����ѡ��ʱ����Ҫһ����Ӧ������̣�
- function getTextChildByOffset(parent, offset) {
- const nodeStack = [parent];
- let curNode = null;
- let curOffset = 0;
- let startOffset = 0;
- while (curNode = nodeStack.pop()) {
- const children = curNode.childNodes;
- for (let i = children.length - 1; i >= 0; i--) {
- nodeStack.push(children[i]);
- }
- if (curNode.nodeType === 3) {
- startOffset = offset - curOffset;
- curOffset += curNode.textContent.length;
- if (curOffset >= offset) {
- break;
- }
- }
- }
- if (!curNode) {
- curNode = parent;
- }
- return {node: curNode, offset: startOffset};
- }
����3��֧�ָ���ѡ�����غ�
�����غϵĸ���ѡ��������һ��������Ǹ�������Ԫ�ص�Ƕ�ף��Ӷ�ʹ�� DOM �ṹ���нϸ��ӵı䶯���������������ܣ�������ʵ���������Ų�ĸ��Ӷȡ���ˣ����� 3.2. ���ᵽ�İ�������Ԫ��ʱ�����ٽ���һЩ�Ը��ӵĴ������������غ�ѡ�������Ա�֤�����������еİ���Ԫ�أ�����Ԫ�ص�Ƕ�ס�
�����ڴ���ʱ������Ҫ�����ĸ����ı�Ƭ�Σ�Text Node����Ϊ���������
������ȫδ����������ֱ�Ӱ����ò��֡�
�������ڱ����������ı��ڵ��һ���֣���ʹ��.splitText()�����֡�
������һ����ȫ���������ı��Σ�����Ҫ�Խڵ���д�����
�����ڴ�ͬʱ��Ϊÿ��ѡ������Ψһ ID�����ö��ı�������Ӧ�� ID���Լ�������ѡ���غ����漰�������� ID�������Ӱ���Ԫ���ϡ����������ĵ��������������Ҫ��� DOM �ṹ��ֻ�ø��°���Ԫ������ ID ����Ӧ�� dataset ���Լ��ɡ�
����6. ��������
����������ϵ�һЩ�����“�ı����ʸ���”�ͻ��������ˡ���ʣ��һЩ“С��”������һ�¡�
����6.1. ����ѡ���Ľ����¼������� click��hover
�������ȣ�����Ϊÿ������ѡ������һ��Ψһ ID��Ȼ���ڸ�ѡ�������еİ���Ԫ���ϼ�¼�� ID ��Ϣ��������data-highlight-id���ԡ�������ѡȡ�غϵIJ��ֿ�����data-highlight-extra-id�����м�¼�غϵ�����ѡ���� ID��
����������������Ԫ�ص� click��hover ���� highlighter ����Ӧ�¼��������ϸ��� ID��
����6.2. ȡ������������������ɾ����
���������ڰ���ʱ֧��ѡ���غϣ���Ӧ���������ᵽ�����������Ҫ����������ˣ���ɾ��ѡȡ����ʱ��Ҳ�������������Ҫ�ֱ�����
����ֱ��ɾ������Ԫ�ء���������ѡ���غϡ�
��������data-highlight-id���Ժ�data-highlight-extra-id���ԡ���ɾ���ĸ��� ID �� data-highlight-id ��ͬ��
����ֻ����data-highlight-extra-id���ԡ���ɾ���ĸ��� ID ֻ�� data-highlight-extra-id�С�
����6.3. ����ǰ�����ɵĶ�̬ҳ����ô�죿
�������ѷ��֣����ַ���ϵ��ı��������ܺ�������ҳ��� DOM �ṹ����Ҫ��֤������ʱ�� DOM �ṹ�ͻ�ԭʱ��һ�£���������ȷ��ԭ��ѡ������ʼ�ڵ�λ�á��ݴˣ���“����”�������Ѻõ�Ӧ���Ǵ������Ⱦ��ҳ�棬��onload�����д�������ѡ����ԭ�ķ������ɡ���ĿǰԽ��Խ���ҳ�棨��ҳ���һ���֣���ǰ����̬���ɵģ��������������ô�����أ�
��������ʵ�ʹ�����Ҳ�������������� —— ҳ��ĺܶ������� ajax �����ǰ����Ⱦ�ġ��ҵĴ�����ʽ�������£�
��������仯��Χ�������������е�“���ڵ�”��documentElement��Ϊ��һ�������������Ԫ�ء���������Ե�ҵ����� id Ϊ article-container ��
�ڼ��ض�̬���ݣ���ô�Ҿͻ�ָ����� article-container Ϊ“���ڵ�”�������������̶ȷ�ֹ�ⲿ�� DOM �䶯Ӱ�쵽����λ�õĶ�λ��������ҳ��İ档
����ȷ������ѡ���Ļ�ԭʱ�����������ݿ����Ƕ�̬���ɣ�������Ҫ�ȵ��ò��ֵ� DOM ��Ⱦ��ɺ��ٵ��û�ԭ����������б�¶�ļ����¼������ڼ����ڴ���������ͨ�� MutationObserver ������־��Ԫ�����жϸò����Ƿ������ɡ�
������¼ҵ��������Ϣ��Ӧ���������İ档�������� DOM �ṹ��������“�����Դ��”�����ȷʵ�и�����������Գ�����ҵ������չʾ����������Ϣ�Ⱦ����������Ϣ���� DOM Ԫ���ϣ������ڸ���ʱȡ����Щ��Ϣ������洢���İ�����ͨ����Щ������Ϣ“ˢ”һ��洢�����ݡ�
����6.4. ����
����ƪ�����⣬��������ϸ�ڵ�����Ͳ�����ƪ����������ˡ���ϸ���ݿ��Բο� web-highlighter ����ֿ����ʵ�֡�
����7. �ܽ�
���������ȴ�“���ʸ���”���ܵ������������⣨��θ����û�ѡ�����ı�����ν�����ѡ����ԭ�����룬���� Selection API��������ȱ����� DOM �ڵ��ʶ�����л���Щ�ֶ�ʵ����“���ʸ���”�ĺ��Ĺ��ܡ�Ȼ�����÷�����Ȼ����һЩʵ�����⣬����ڵ� 5 ���ֽ�һ����������Ӧ�Ľ��������
��������ʵ�ʿ����ľ��飬�ҷ��ֽ����������“���ʸ���”��������Ĵ������һ��ͨ���ԣ���˰Ѻ��IJ��ֵ�Դ���װ���˶����Ŀ� web-highlighter���й��� github��Ҳ����ͨ�� npm ��װ��
���ѷ��������ϲ�Ʒҵ�����ĸ�������һ�д��뼴�ɿ�����
- (new Highlighter()).run();
��������IE 10/11��Edge��Firefox 52+��Chrome 15+��Safari 5.1+��Opera 15+��
ת����ע���� ����ת���ԣ���˼��Դ�� http://www.aseoe.com/show-12-1126-1.html